 GriffinDetector: a novel pipeline to scan fusion genes
GriffinDetector: a novel pipeline to scan fusion genes
The main purpose of this program is to detect candidate fusion genes from annotated genomes. The fusion genes here are especially means the fusion genes that combined from two parental genes.
Program installation:
This pipeline was written by Perl script, it requires makeblastdb and blastp which belong to BLAST+ package. Before running this program, please make sure the BLAST+ package was installed. We suggest making a link at /usr/local/bin/.
This pipeline passed the test based on the CentOS Linux release 6.0, Perl version 5.10, BLAST+ version 2.2.28, with rice tribe genome data.
The source code of GriffinDetector is available in the github or zenodo.
Data preparation:
- The phylogeny for the species are interested (at least three species)
- The protein sequences for these species
- The gff3 file for the relative species (the modification may be required)
- The outgroup species and focus species should explicit
Main data of the paper
| species | gff | fasta |
| Arabidopsis thaliana | TAIR10_GFF3_genes.gff | TAIR10_pep.fasta |
| Leersia perrieri | L.perrieri.maker.gff | L.perrieri.maker.proteins.fasta |
| Oryza barthii | O.barthii.maker.gff | O.barthii.maker.proteins.fasta |
| Oryza brachyantha | O.brachyantha.maker.gff | O.brachyantha.maker.proteins.fasta |
| Oryza glaberrima | O.glaberrima.maker.gff | O.glaberrima.maker.proteins.fasta |
| Oryza longistaminta | O.longistaminta.maker.gff | O.longistaminta.maker.proteins.fasta |
| Oryza punctata | O.punctata.maker.gff | O.punctata.maker.proteins.fasta |
| Oryza rufipogon | O.rufipogon.maker.gff | O.rufipogon.maker.protein.fasta |
| Oryza sativa.ssp.indica | O.sativa.ssp.indica.gff | O.sativa.ssp.indica.maker.proteins.fasta |
| Oryza sativa.ssp.japonica | O.sativa.ssp.japonica.gff | O.sativa.ssp.japonica.maker.proteins.fasta |
Flowchart:
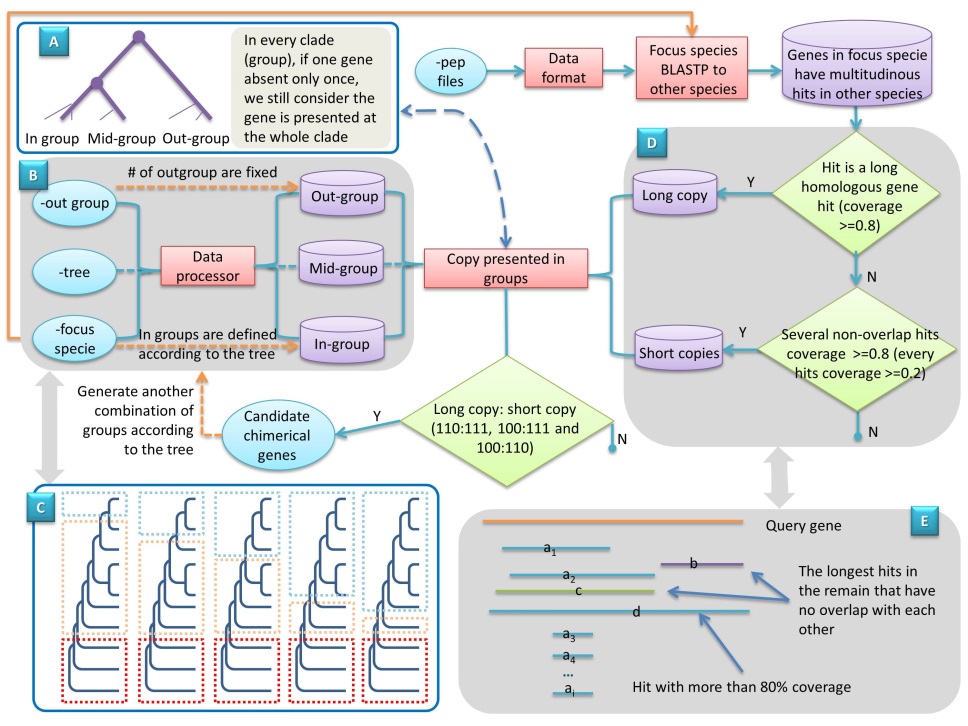
The advantages of the pipeline:
- This pipeline will automatically detected the fusion genes based on the phylogeny with several species;
- It was very easy to adjust the phylogeny, annotation and the combination of species to get fusion genes in focus species as more as possible with simple modification;
- Since this pipeline works on several genomes, the abundance of genome data will largely relieve the bad affect caused by imperfect assembling and annotation;
Notation:
- The hit coverage of the query gene and the hit length in some cases may not accurate;
- The gene loss events was assume not appear in groups, so the final fusion genes may underestimated;
- The annotation of focus species may affect the final results a lot.
Download: Version 1.1
Citation:
Bug Report:
FAQs: